
In this article, we examine the results comparing commercial giants (OpenAI, Google) with local vLLMs (Gemma (still Google), Qwen, SmolVLM) and classic computer vision (YOLO).
These findings also apply to healthcare, Biotech, or MedTech. The constraints are totally identical: you need binary decisions, strict safety thresholds, and real-time operation under tight deployment limits.
We analyze why models can’t evaluate the amount of beans in a dish, how a hybrid YOLO + LLM system achieved a phenomenal 99% accuracy, and why running these on underpowered hardware (like the Debix B) remains a utopia – for now.
Our task was to create a system capable of human-level discernment between “good” and “bad” samples, accounting for complex criteria:
- portion size,
- degree of doneness,
- ingredient integrity,
- and plating.
To achieve this, we prepared a balanced dataset of 1,046 images, split equally between high-quality and defective samples.
The Battle of Models and the “Bean Factor”
The overall performance of vision language models (vLLMs) in QA tasks is limited by specific criteria requiring quantitative assessment. Meanwhile, local models proved to be more predictable and effective at following instructions than their paid API competitors.
Analysis showed that almost all models share a similar level of visual perception (dish recognition fluctuates between 54–60%). The main difference lies in the QA logic – specifically, how the model interprets the concept of a “defect.” The primary blocker for accuracy across all models without exception was the “beans portion size” criterion. Models systematically fail at estimating volume “by eye,” which artificially lowers the overall rating.
We are observing a curious paradox: the gap between the ‘best’ and ‘average’ model is minimal. Newer versions (e.g., the transition from Gemini 2.0 to 3.0) do not guarantee a quality jump in such narrow niches.
| Model | Dish Recognition | QA Accuracy | QA (Ignoring Beans) |
| GPT-4o | 58% | 53% | 65% |
| Gemini 2.0 Flash | 58% | 52% | 64% |
| Gemini 3 Flash | 60% | 51% | 63% |
| Gemini 3 Pro | 60% | 54% | 67% |
| GPT-5.2 | 54% | 50% | 60% |
The numbers speak for themselves: The local model Qwen2-VL-8B-Thinking (or Qwen3-VL-8B-Thinking) showed the best overall QA result at 58%, surpassing GPT-4o (53%) and Gemini 1.5 Pro (54%).
| Model | Dish Recognition | QA Accuracy | QA (Ignoring Beans) |
| Gemma-3 4B (local) | 56% | 55% | 65% |
| Qwen3-VL-8B | 58% | 58% | 69% |
However, the most interesting shift occurs when the problematic “beans” criterion is ignored:
- Qwen-VL jumps to 69%.
- Gemini Pro reaches 67%.
- GPT-4o hits 65%.
This proves that most models already handle other defects quite well (e.g., a broken egg or burnt bacon), and the issue lies with one specific ingredient.
Local vLLMs (notably Qwen and Gemma) are leaders in stability within our pipeline. They allow for controlled costs and latency without sacrificing quality compared to the giants, provided the issue of quantitative estimation (portions) is addressed.
The Hybrid Approach and the Harsh Reality of Hardware
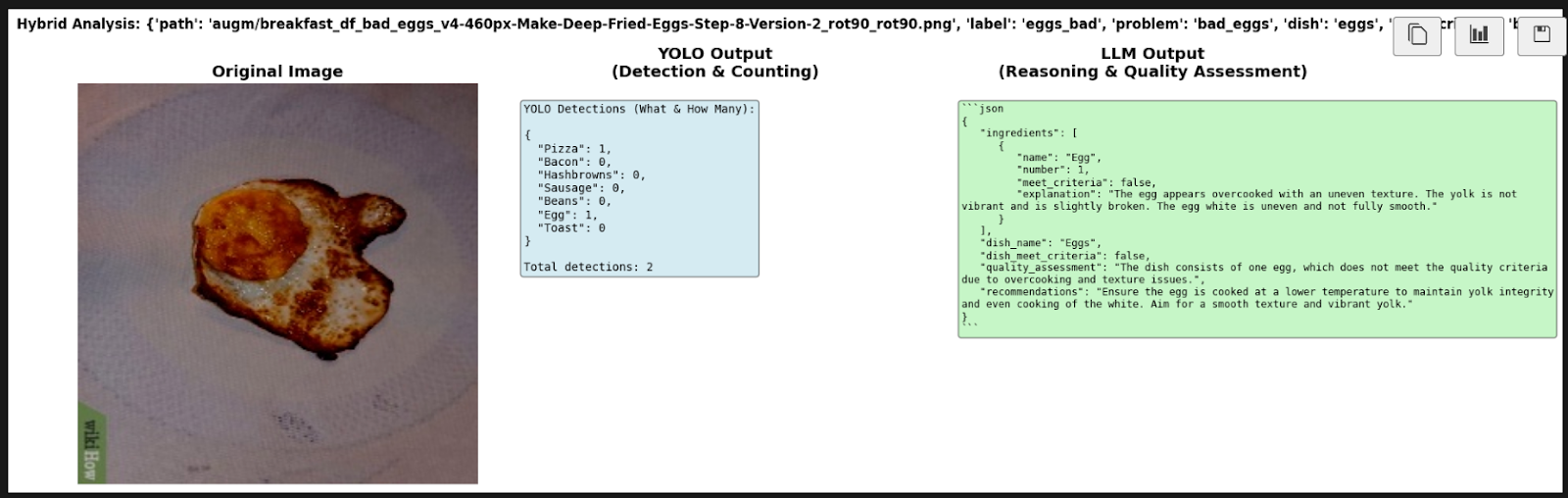
Using “pure” approaches (YOLO-only or LLM-only) presents critical vulnerabilities. The game-changing solution was a hybrid approach that combines the strengths of both technologies. However, deploying such systems on Edge devices with limited computational resources is currently inefficient.
The classic YOLO-World v2 detector, without fine-tuning, is excellent at finding objects but systematically fails at counting (e.g., number of toasts or sausages) and completely lacks context for quality (it cannot see if food is spoiled). Conversely, LLMs understand context but often “hallucinate” regarding the presence of ingredients.
The hybrid system works as follows:
- YOLO detects and counts (creating a raw JSON of facts).
- LLM receives the photo + the JSON and makes a logical conclusion.
The results of such an approach:
| Model | Dish Recognition | QA Accuracy | QA (Ignoring Beans) |
| YOLO-World (pure) | 55% | 51.6% | 61.6% |
| YOLO + GPT-4o (hybrid) | 99.2%(best) | 52.2% | 63.4% |
The comparison highlights a stark contrast:
- Pure YOLO: 0% bacon recognition accuracy, 55% overall dish recognition.
- Hybrid (YOLO + LLM): 99.2% dish recognition accuracy! This is an absolute record.
- The hybrid’s ingredient counting accuracy is also high: Pizza – 98.8%, Hashbrowns – 91.4%.
The technical side. However, running this on a device like the Debix B turned into an ordeal. Due to a lack of NPU support and outdated libraries, processing a single frame could take ~63 minutes. Even with ONNX optimization on a powerful PC, it takes 15 seconds – still far from real-time.
The hybrid architecture of “Object Detection + Logical Reasoning” is the undisputed leader for the accurate identification of dishes and ingredients.
However, for production use, it requires either powerful cloud servers or significantly more performant Edge platforms (such as NVIDIA Jetson), as current budget boards (Debix) cannot handle modern multimodal models.


Conclusion
Reliable, real-time Food Quality Assurance it’s a system design problem. After thorough testing, the idea is clear – chasing the “smartest” monolithic model is not a valid solution:
- Local Models are the New Standard: Qwen and Gemma didn’t just compete; they outperformed GPT-4o in stability for specific QA tasks.
- The “Bean” Paradox: Specialized problems require specialized logic. No amount of general-purpose “intelligence” can replace a model trained to understand specific volume constraints.
- The Hybrid Advantage: Combining “eyes” (YOLO) for raw data with “brains” (LLMs) for logic pushed our accuracy to 99.2%.
- Hardware is the Final Frontier: You can’t run a Ferrari engine on a bicycle frame. Edge deployment on budget boards like the Debix remains a bottleneck that requires either better hardware or aggressive optimization.
Betting everything on a single, monolithic model is both insufficient and risky. Our applied work in healthcare illustrates this directly.
In our deployed LLM-powered healthcare assistant and immersive VR health studio, we didn’t achieve production-grade performance by finding a “better” model. We achieved it by explicitly separating responsibilities:
- Deterministic pipelines handle measurements and control.
- LLMs handle interpretation and human interaction.
- Robust infrastructure ensures real-time operation.
The deployed system enables real-time organ-level analytics, personalized notifications, and seamless user login across VR and web.
Check how these principles are appliedDeliberately combining vision models, language models, and deterministic logic is what will unlock production-ready AI in healthcare, Biotech, and beyond.
Ready to build? Stop waiting for the next API update and start designing your hybrid pipeline. Let’s move AI from the sandbox to the production line.