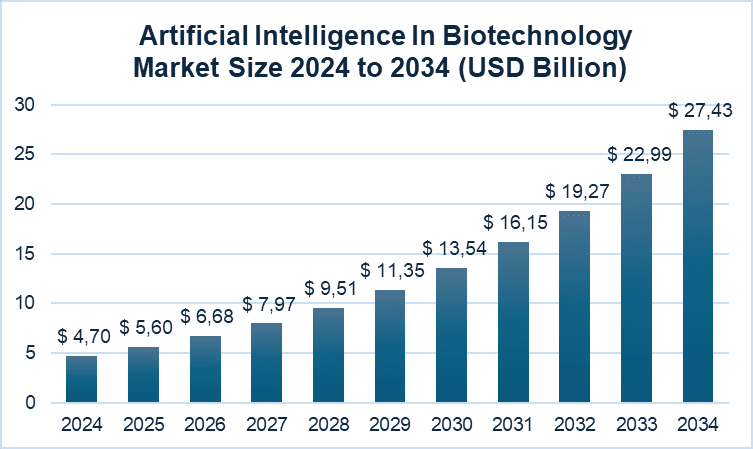
The rapid growth of AI implementation in biotechnology isn’t something unexpected. This market was valued at USD 4.70 billion in 2024 and is expected to reach USD 5.60 billion in 2025 and approximately USD 27.43 billion by 2034, with a CAGR of 19.29% (Precedence Research).
Artificial intelligence has emerged as a driving force in biotechnology, revolutionizing the entire process of drug discovery and development. At the same time, important questions about its efficacy and safety remain unresolved.
As a result, AI in biotech is a story of both progress and uncertainty. Let’s look at the current situation, focusing on new approaches, challenges, and successes.
One of our projects – AI-Assisted Screening Tool – demonstrates how agentic AI can streamline diagnostic workflows by automating image analysis, prioritizing high-risk cases, and reducing clinician workload.
Read the Full CaseAI Drug Discovery in 2025: From Hype to Hard Questions
Nowadays, artificial intelligence is widely used in drug development, clinical trials, and operational efficiency, not just by AI biotech startups, but also by industry giants such as Johnson & Johnson (J&J), Moderna, and Pfizer.
In 2025, the share of AI-discovered drugs is projected to reach 30% (World Economic Forum). AI can accelerate workflows and decrease the cost of advancing a new molecule to the preclinical stage. For example, such technologies can save up to 40% of the time and 30% of the cost for challenging targets (Mikulic, 2025).
But is its future as bright as people hope?
The industry has already faced obstacles in adopting AI systems. Healthcare outcomes may suffer if algorithms are biased, as treatments may not work equally well for all patients. In addition, many models operate as “black boxes”, creating challenges for the approval of AI-designed drugs and devices. Combined with safety setbacks, such as Sarepta’s AAV-related issues, these factors have raised questions about the value of applying AI to drug design and development.
Unfortunately, early excitement isn’t always followed by real results. Despite progress, few AI-designed drugs have entered clinical trials, and none have advanced to Phase 3. Moreover, there is no significant difference in the Phase 2 trial failure rates between AI-discovered drugs and traditional ones.
Rentosertib: First AI-Designed Drug Enters Phase II Trials
A rare exception to the overall disappointment with AI-designed drugs, Insilico Medicine’s small-molecule TNIK inhibitor completed a Phase 2a trial.
Rentosertib is the first reported case where an AI platform enabled the discovery of both a disease-associated target and a compound for its treatment. This approach reduced the time required for preclinical candidate nomination to just 18 months and advanced to Phase 0/1 clinical testing in under 30 months.
Despite the Phase 2a study, which showed the asset was generally safe and well-tolerated, a comprehensive assessment of long-term safety and efficacy will only be possible after more in-depth studies, as the present trial had several limitations (small cohort size, geographical and demographic homogeneity of participants, and short follow-up period).
At the same time, these results confirmed both the compound’s therapeutic potential and the ability of AI-driven target discovery and drug design to streamline drug development (Xu et al., 2025).
MULTICOM4 Boosts AlphaFold Accuracy in Protein Complex Structure Prediction
Another successful application of AI in biotechnology is the use of ML-based tools in structural biology. While different AlphaFold models have been created for specific purposes, they still don’t completely meet users’ needs.
AlphaFold2-Multimer and AlphaFold3 have notably improved quaternary structure modeling. However, their accuracy for complexes doesn’t reach the level achieved for single proteins. Among the key challenges are modeling large assemblies and handling protein complexes with poor MSAs or unknown subunit counts.
To overcome these limitations, Dr. Cheng’s research group has developed MULTICOM4. Essentially, this system wraps AlphaFold’s models in an additional layer of ML-driven components that significantly enhances their performance.
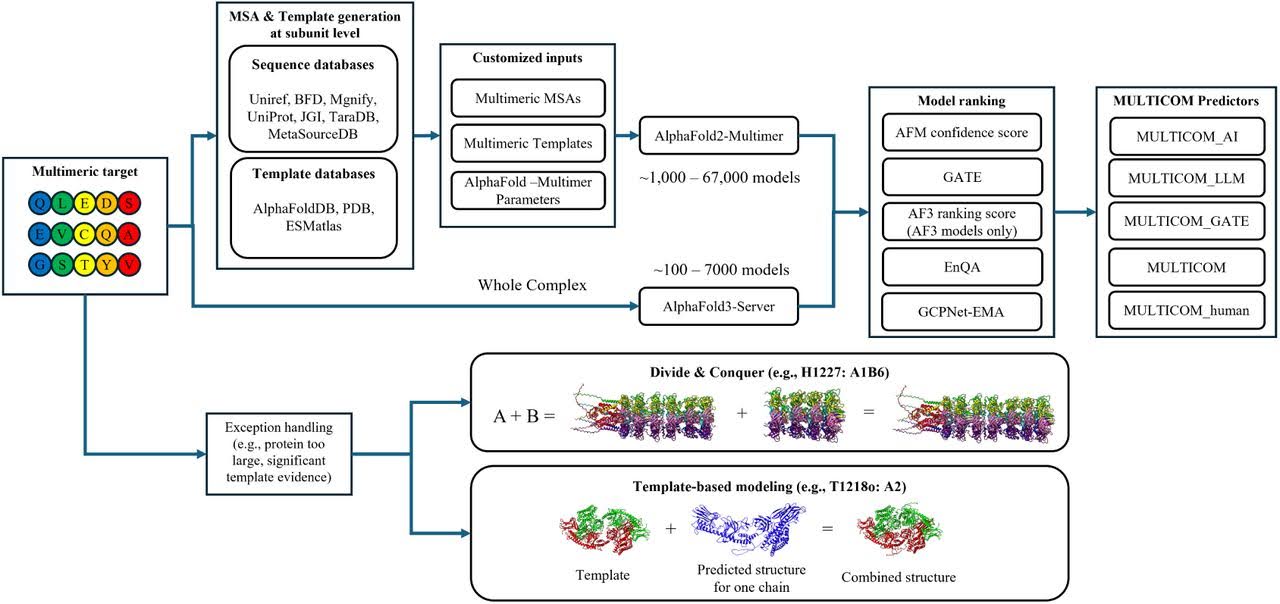
Key advantages of MULTICOM4 over AlphaFold2 and AlphaFold3:
- Has a higher chance of capturing correct conformations by combining transformer-based and diffusion-based deep learning architectures;
- Uses improved MSAs that integrate both sequence homology and structural similarity;
- Can predict structures of protein complexes even with unknown stoichiometry;
- Provides enhanced model ranking by combining multiple ranking scores and methods;
- Overcomes limitations in handling large protein complexes and challenging targets with poorly defined interaction interfaces by using divide-and-conquer modeling and traditional template-based modeling techniques.
The authors of MULTICOM4 identify key remaining challenges: improving the reliability of model ranking for difficult targets, such as antibodies, and generating high-quality structures for large, non-globular protein complexes, such as filaments (Liu et al., 2025).

Get a one-on-one consultation with Ivan Izonin, PhD, Scientific Advisor in Artificial Intelligence, and discover how advanced AI approaches can accelerate your biotech research and innovation.
Book a ConsultationAI Agents Are Revolutionizing the Biotechnology Industry
Self-driving cars and robotic process automation are no longer something novel, and it’s entirely expected that biotech and pharma companies are interested in optimization with similar systems.
AI agents can accelerate, streamline, and enhance the entire drug development process by implementing large language models (LLMs). No-code AI tools enable the creation of AI-driven research workflows without requiring in-depth knowledge of software engineering or data science.
It may sound like science fiction, but AI is already acting as a scientist. It can generate and test hypotheses independently. Such multi-agent systems are used to uncover new links between genes and diseases, design new drug molecules, and predict materials for drug delivery.
However, due to limitations and errors, these systems won’t replace workers anytime soon. It’s also a challenge for regulatory agencies, as now they can’t ensure transparency, ethical standards, and control biased decisions. And of course, such technologies still require careful oversight by human specialists.
BioMARS: Autonomous Lab Automation via Multi-Agent AI
Robotic automation and artificial intelligence can help with key limitations of experimental biology by improving reproducibility, enabling higher throughput, and reducing human-dependent variability.
However, it’s difficult to achieve fully autonomous systems due to the complexity of biological protocols. Current solutions often need significant manual oversight and struggle to handle unexpected deviations in procedures.
Researchers at the University of Science and Technology of China (USTC) found a promising solution to these challenges in large language models (LLMs) and vision–language models (VLMs). They developed an intelligent agent that may fully automate biological experiments by combining LLMs, multimodal perception, and robotic control. To overcome the limitations of previous autonomous systems, BioMARS was provided with direct access to scientific literature, coding environments, and robotic platforms.
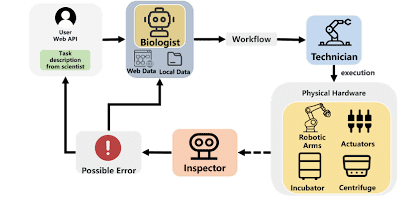
As shown in the architecture, the system consists of three AI agents:
- Biologist Agent: designs experimental protocols;
- Technician Agent: translates protocols into structured instructions for lab hardware;
- Inspector Agent: monitors experiments with visual and sensor data to detect errors.
While BioMARS performs well in standard tasks, it still needs human supervision for unusual or customized experiments. It also depends on existing procedures, making it challenging to adjust for diverse laboratory contexts or handle unexpected problems in real time (Qiu et al., 2025).
At this stage, it’s too early to call this a turning point for the industry, as it remains a research system rather than a commercial prototype and still has critical limitations.
CRISPR-GPT and the Future of Gene Editing
Gene editing has transformed biological research and medicine. However, even techniques as popular as CRISPR-Cas are still very complex, particularly for newcomers.
AI models are addressing this complexity. To address this, researchers from Stanford University, Princeton University, and Google DeepMind have developed CRISPR-GPT. This LLM-powered multi-agent system serves as an AI copilot for gene editing.
It supports four primary gene-editing modalities (knockout, base editing, prime editing, and epigenetic editing). It offers three user interaction modes designed for different levels of expertise and needs, making the technology highly accessible and valuable.
CRISPR-GPT consists of four main components: the User Proxy, LLM Planner, Task Executor, and Tool Provider, along with a Gene-Editing Bench that contains numerous test cases. They can select suitable CRISPR systems, design guide RNAs, and choose the most appropriate delivery methods. They also develop experimental protocols, analyze laboratory results, and adjust subsequent steps as needed.
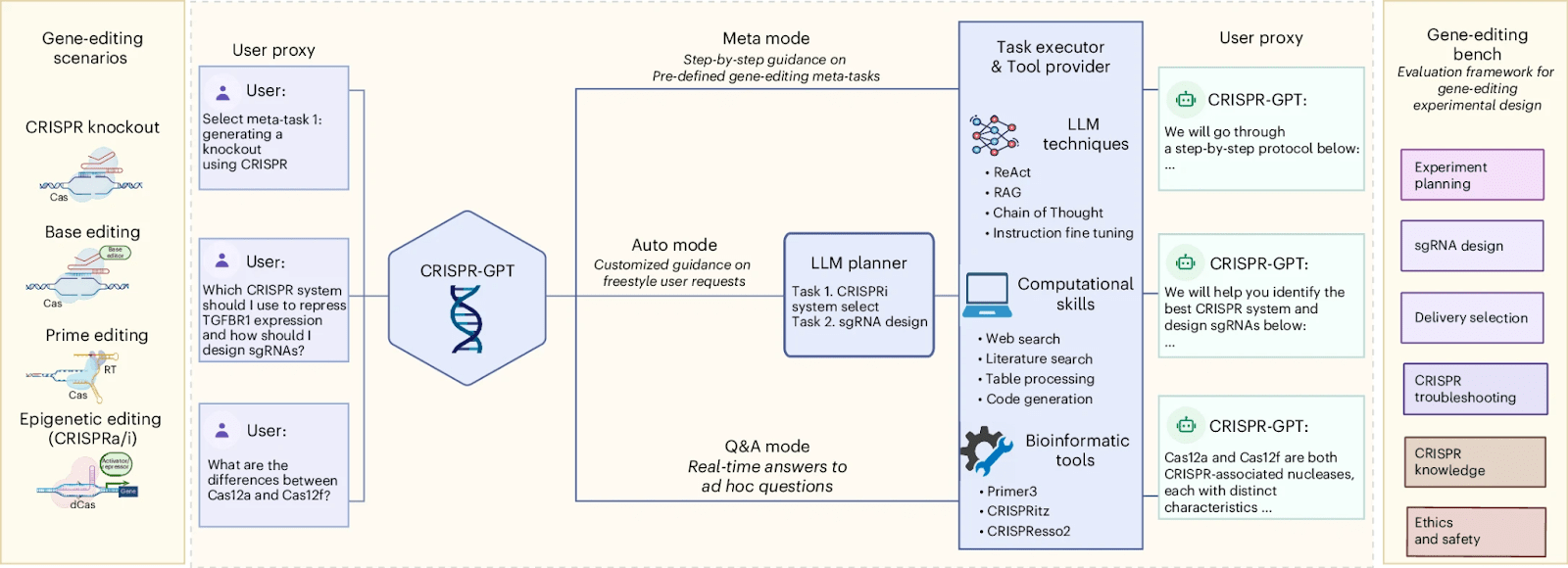
The authors tested the CRISPR-GPT system in real experiments run by junior researchers with no experience in gene editing, and, excitingly, the very first attempt was successful. On the other hand, simplified gene editing could be used to create bioweapons. However, the developers assure that they’ve built in safeguards to prevent this.
In the future, CRISPR-GPT could be further developed by linking it to advanced genome models, plasmid design tools, and other AI systems to support tasks beyond gene editing, potentially even enabling fully automated experiments through integration with lab automation and robotics (Qu et al., 2025).
AI-Driven Protein Folding: Boltz-2 Sets a New Standard
Today, molecular design often relies on all-atom co-folding models that can predict the 3D structures of molecular interactions. However, these models struggle with small molecules, which are prevalent in pharmaceuticals, chemicals, and consumer products.
Small molecule binding affinity is not only crucial for drug function but also a significant challenge in drug design. Until now, the only alternative to lab experiments has been long physics-based simulations, which are also very slow and costly.
Recently, the Boltz team released Boltz-2, an improved version of their Boltz-1, which has already been widely adopted, even by top AI biotech companies.
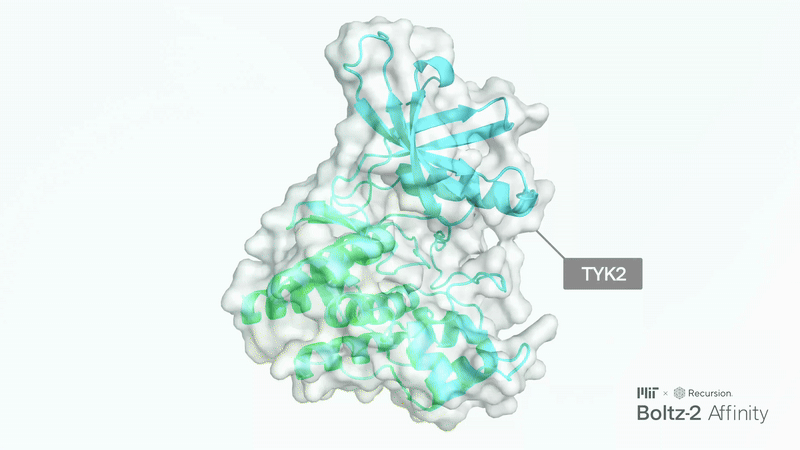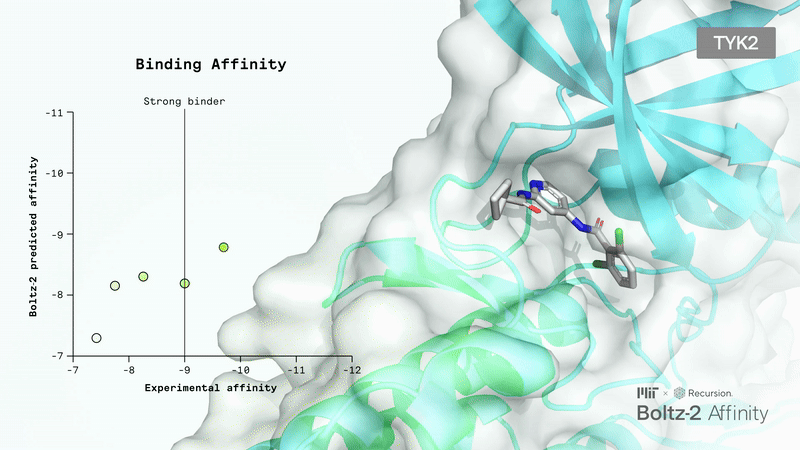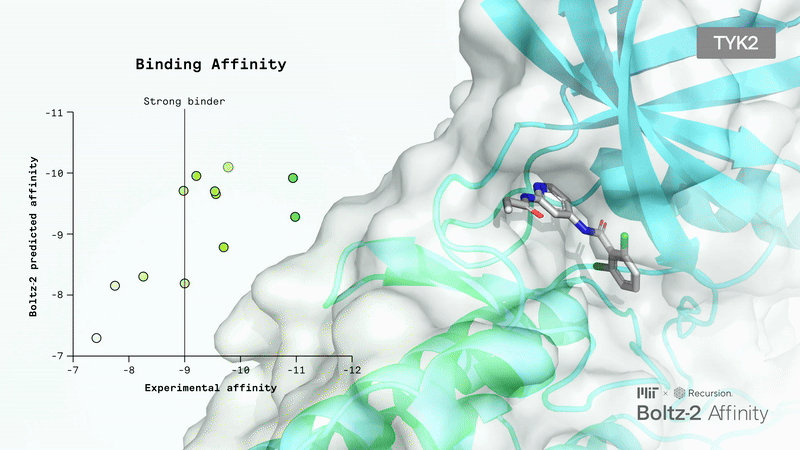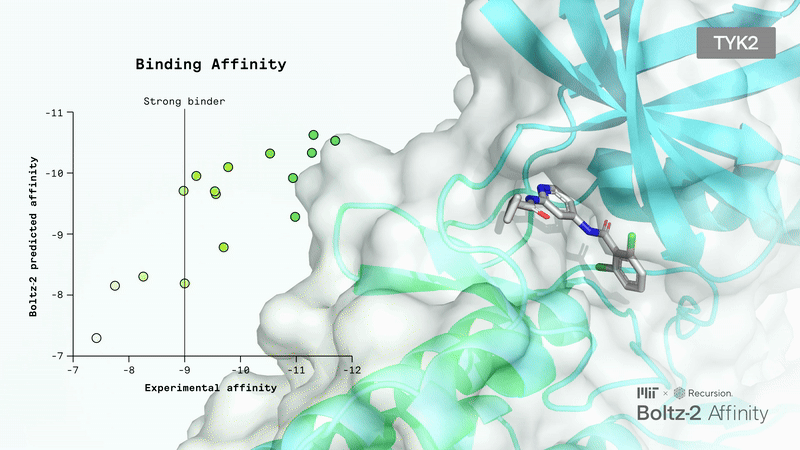
The main upgrades include unified structure and affinity prediction, better controllability, GPU optimizations, and the integration of a large collection of synthetic and molecular dynamics training data. Responding to user feedback, the developers also added more precise controls: you can now set contact constraints, use templates to guide predictions, or match results to specific experimental methods.
Boltz-2 has the potential to be a breakthrough for the industry, as it finally makes early-stage in silico screening practical by combining FEP-level accuracy with speeds up to 1000 times faster than existing methods.
Building an AI Agent for Biotech Analytics: Step-by-Step
by Alex Gurbych, PhD
In this guide, we’ll build an AI agent that lets users query data in plain English and receive interactive charts as responses, so you can literally talk to your data.
1. Setting up the AI Agent
- Choose the following parameters: Tools Agent, Connected Chat Trigger Node,
{{ $json.chatInput }}. - System Message: "Role: You are a DB assistant who answers user questions by querying Google BigQuery."
- Target Dataset:
bigquery-public-data.human_variant_annotation(Always wrap the dataset name in back-ticks in every SQL query.)
Workflow (STRICTLY follow in order):
1. List tables
- Tool: “Get DB Schema and Tables list”
- Always call this first to retrieve the complete list of tables (with schema names).
2. Generate a single-table Google SQL query
- Choose one table from the
INPUT SCHEMA(no joins, no sub-queries across tables). - Only reference columns that appear in that table’s column list from the
INPUT SCHEMAoutput. - Prefix the table with its exact schema name.
- Add
"LIMIT 30"to the end of every query. - Write the SQL in valid Google BigQuery Standard SQL.
3. Run the query
- Tool: “Execute BigQuery query”.
4. Craft the textual answer
- The result set in plain language (counts, top-N, averages, etc.).
5. Build a QuickChart bar chart with the QuickChart tool
- Tool: “QuickChart”
- Base the chart on the same result set.
- Chart config must match this template (edit labels/data as needed):
{
"type": "bar",
"data": {
"labels": ["Label1", "Label2", "..." },
"datasets": [{
"label": "Your-Metric-Name",
"data": [value1, value2, …]
}]
}
}- Encode the JSON and embed it exactly like this (it should be an image):
! [Chart] (https://quickchart.io/chart?c=<encoded_chart_config>)
Constraints:
- Use only tables and columns that appear in the
INPUT SCHEMAoutput. - Never query more than one table or use any kind of joins.
- Always generate a chart using the QuickChart tool
- Always include the schema prefix in the table reference.
- Always limit results to 30 rows.
- The final response must include a Markdown image line with the QuickChart URL and text.
- SQL must be a valid BigQuery Standard SQL.
2. Setting up OpenAI Chat Model
Create new credential:
- API Key: go to platform.openai.com and create a new secret Key.
- Base URL: https://api.openai.com/v1.
3. Setting up BigQuery Node
Create two BigQuery tools and rename the nodes: the first one to “Execute BigQuery query” and the second one to “Get DB schema and tables list”.
Set up a BigQuery account:
- Create a new credential (connect using Service Account).
- Create the Service Account Email and a Private Key:
- Go to Google Cloud > login to Console > go to API and services > find BigQuery API > click Enable button > go to Service Accounts > create Service Account (name:
big-query-service-account) > copy an email address and insert into Service Account Email. - List of Service Accounts > Actions > Manage keys > create a new Key (type JSON) > download it to PC > copy the Key from it and insert.
- Tool Description: Set Manually.
- Descriptions: “Get all the data from BigQuery, make sure you append the tables with the correct schema. Every table is associated with some schema in the database.”.
- Copy the Project ID in the file that was downloaded during Service Account creation.
- SQL Query :
“ {{ $fromAI("sql_statement") }} ”.
- Go to Google Cloud > login to Console > go to API and services > find BigQuery API > click Enable button > go to Service Accounts > create Service Account (name:
4. Set up a second node
The process is almost the same, with a few exceptions:
- Descriptions: “Get a list of all tables with their schema in the database”.
- SQL Query :
SELECT
table_name,
ordinal_position,
column_name,
data_type,
is_nullable
FROM
`bigquery-public-data.human_variant_annotation.INFORMATION_SCHEMA.COLUMNS`
ORDER BY
table_name,
ordinal_position5. Setting up QuickChart:
- Create new Tool (QuickChart).
- Description: “Create a chart via QuickChart”.
- Chart Type: Bar Chart.
- Add Labels: From Array.
- Labels Array (formulated as expretions):
“ {{ [$fromAI("data")] }} ”. - Data (formulated as expretions):
“ {{ [$fromAI("data")] }} ”. - Put output in Field: data.
Congratulations, we are done! Now you can test it. For example, ask: “How many variants are there per chromosome?” or “What are the top 10 most frequent variant types?”.
Conclusion
Today, artificial intelligence already has a significant influence on biotechnology and will likely shape its further development. However, this progress is followed by unresolved challenges.
To sum up, the future of AI depends on our ability to manage problems of its implementation. AI’s potential can be fully unlocked only if the industry critically analyzes new technologies and their adoption.
If you’re interested in applying AI to biotechnology, feel free to reach out to us at blackthorn.ai. You can also book a training session or consultation with Alex Gurbych, PhD, CEO.

