
1. What are LLMs?
Large language models are a family of neural networks, developed to solve various natural language processing tasks. Auto-regressive LLMs are the most used at the time. They work with text represented as a sequence of tokens – basic units that may be subwords, words, numbers, or punctuation marks. They are trained to predict the next token based on the context of previous tokens. By predicting tokens sequentially, they could generate complete texts.
Trained on vast and diverse texts from different domains, such models are named foundational, emphasizing their ability to be applied for different downstream tasks. They show incredible natural language understanding and reasoning ability but they have limitations.
Some of the key limitations include:
- LLMs can express unexpected behavior such as failing to correctly follow instructions or generating biased or toxic messages.
- They often lack domain-specific knowledge and are unfamiliar with private business processes.
- They have a knowledge cutoff: they know only information obtained before their training. So they can’t consider events and facts that happened or discovered after this time point.
- There are privacy concerns. If trained on some private data they can disclose it.
To address the problems, especially described in 1st point, foundational models often were instruction-tuned using reinforcement learning from human feedback (RLHF). These models show the ability to follow a broad class of written instructions and produce outputs more aligned with user intentions. Such fine-tuned models are usually referred as Instruct (InstructGPT, Mistral 7B Instruct, or Llama 3-Instruct).
Integrating LLM applications with custom data can significantly improve model knowledge in target domains, and enhance answers relevance and accuracy.
In the next chapter, we will dive into the technical aspects of efficiently managing the challenges of data ingestion for LLMs.
2. How to use LLMs with custom data?
2.1. Prompt Engineering
Effective implementation of LLMs-powered systems requires careful consideration. Running out-of-the-box LLM on custom data you may face suboptimal results if the model is not properly tuned and integrated.
It is crucial to understand the concept of a prompt, which is a query or instruction given to LLM. It sets the task for the model and guides how it could be completed. It may also provide examples and some additional information.
The most straightforward way to integrate custom data with LLMs is using prompt engineering. That means you construct a model prompt to include information about the topic, context, tone, and expected structure of the response. Carefully executed prompt engineering can significantly improve the accuracy and relevance of the model outputs but requires significant effort to determine which data helps the model answer the question.
The goal of prompt engineering is to enrich the input prompt with enough context to guide the model toward generating an expected outcome. Efficient data ingestion for LLMs requires:
- Identification of key information that is critical for the query;
- Structuring the prompt to naturally integrate these details without overloading the model;
- Refining the context during conversation to balance clarity and relevance.
2.2. Retrieval Augmented Generation
To address the challenges of data ingestion for LLMs, Retrieval Augmented Generation (RAG) technologies have been developed. They supplement models with external data relevant to each query. This allows not only more accurate answers but also enables dynamic integration of up-to-date information from external databases without the need for retraining.
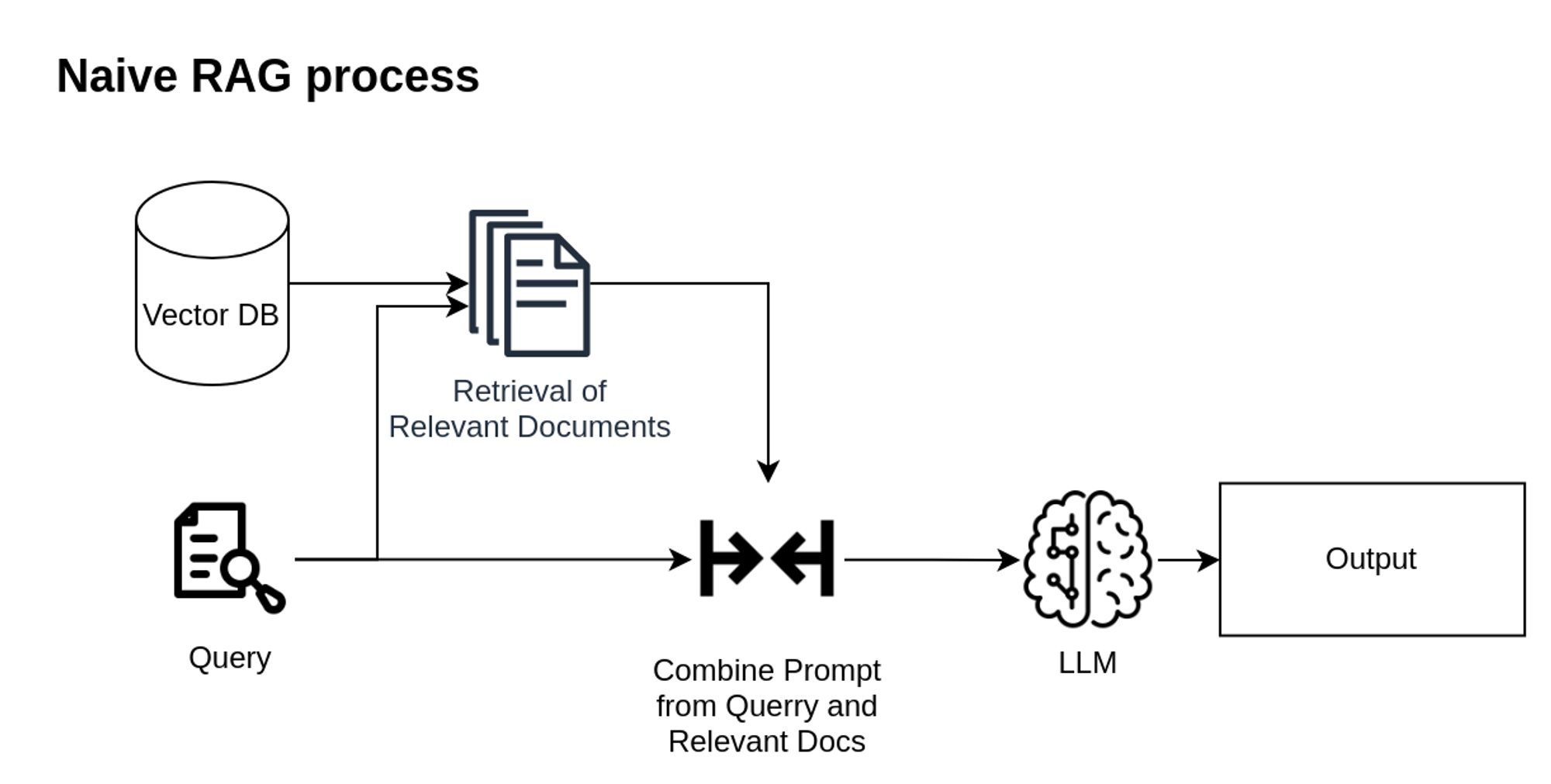
Naive RAG follows a process including indexing, retrieval, and generation.
Indexing is the initial phase, which prepares a knowledge base that allows fast and efficient retrieval of required information. Below is a diagram illustrating the substeps of the indexing process.
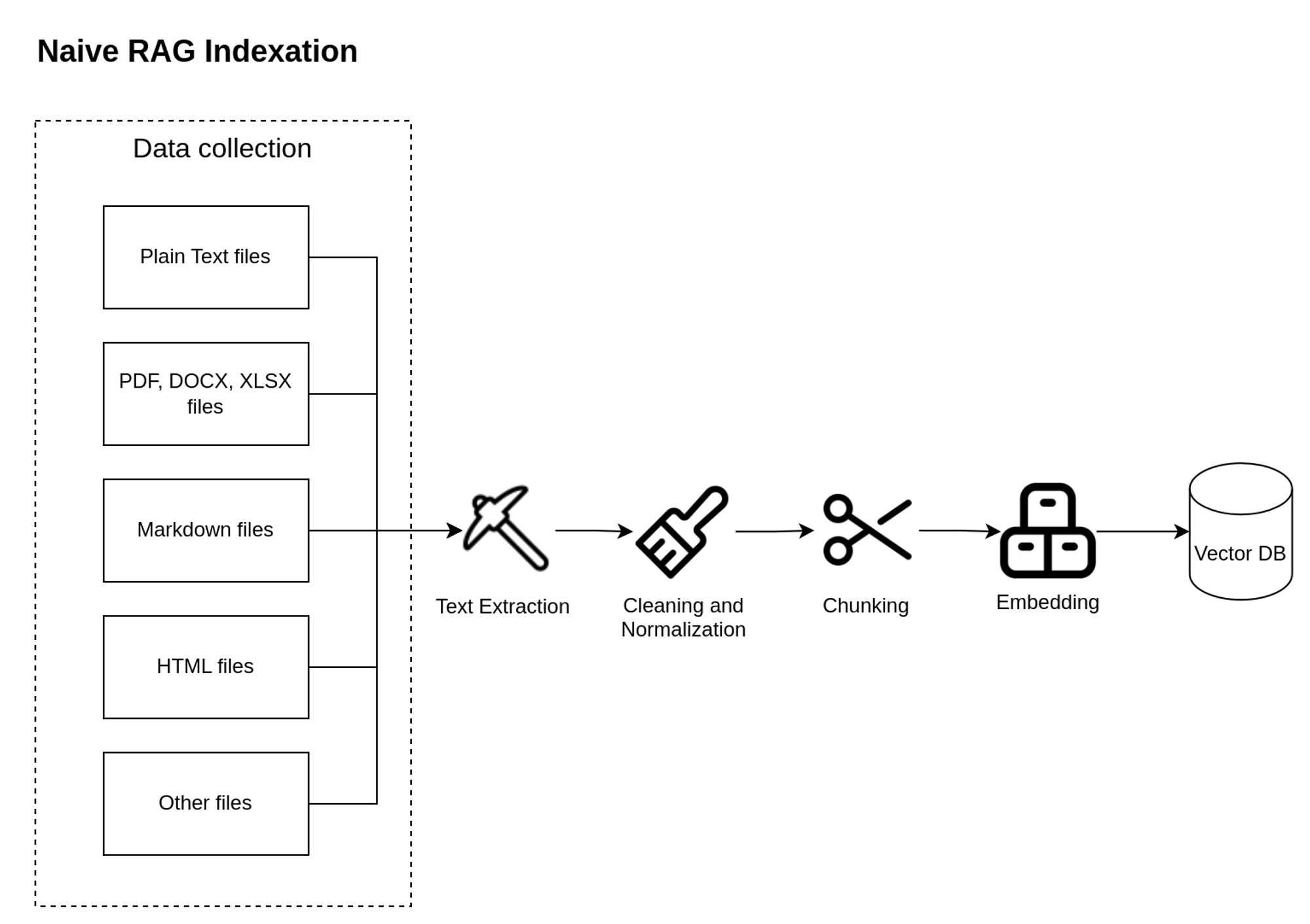
Each indexing substep plays a crucial role in effective data ingestion for LLMs:
- Text Extraction: Plain text is extracted from various sources like research papers, books, web pages, spreadsheets, and databases.
- Cleaning and Normalization: Remove irrelevant information like formatting, punctuation, special symbols, or stop words, to ensure only useful information is provided to the LLM model. Additional normalization techniques such as stemming or lemmatization can be applied optionally.
- Chunking: After cleaning the data, the text is split into chunks. This allows more focused searches and helps to effectively address the context limitations of language models.
- Embedding: Chunks are encoded as vectors using an embedding model to enable efficient retrieval. The embedding model allows the representation of text as a vector of numbers, which captures important features of the data such as semantics like text topic and context.
- Storage: Embedded chunks are saved in a vector database. This storage is carefully designed to enable efficient similarity searches and allows quick retrieval of the most relevant information for the query.
Retrieval process triggered by user query. The system encodes the query using the same embedding model used during indexing. The system selects the top-k similar chunks from the vector database based on similarity scores.
The Generation process starts with synthesizing an LLM prompt using the user query and selected chunks and the model generates a response.
When generally application of Naive RAG technologies increases model performance and effectively reduces the frequency of factually incorrect responses, it faces challenges during multiple processes:
- Retrieval: Sometimes irrelevant or nonoptimal chunks may be selected leading to a lack of crucial information.
- Prompt Synthesis: Integrating user queries with different document chunks may result in confusing prompts. Sometimes similar information is selected leading to redundancy.
- Generation: Even enriched with relevant information, the model may still face hallucinations.
RAG is currently continually evolving. Depending on the nature of custom data a variety of knowledge stores may be employed including relational or graph databases. We will cover only selected RAG variants, but a more detailed review can be found in A Survey on Retrieval-Augmented Text Generation for Large Language Models.
2.3. Advanced RAG
To overcome the challenges of Naive RAG during the Retrieval and Prompt Synthesis phases, Advanced RAG was proposed.
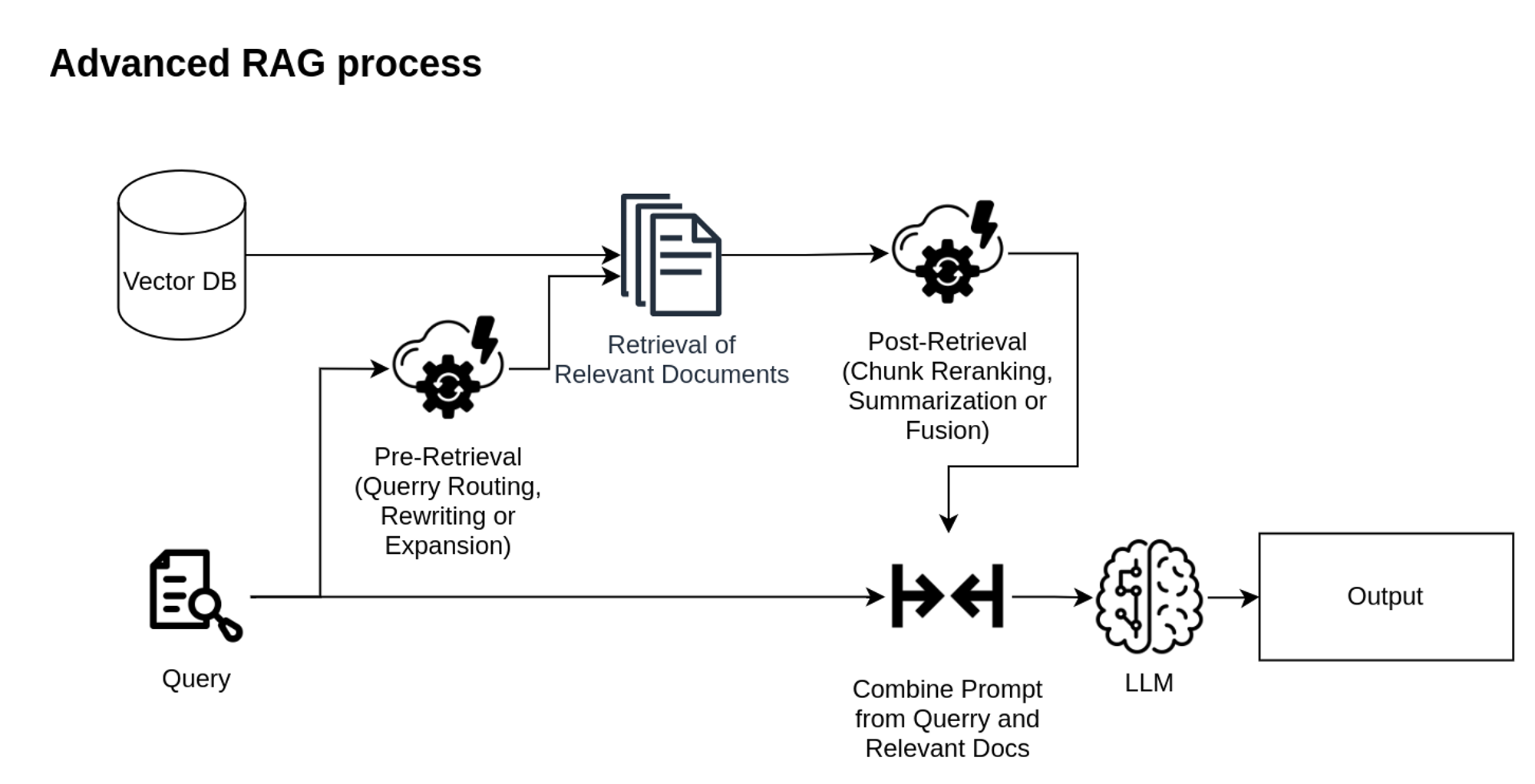
Advanced RAG includes 2 additional steps: Pre-Retrieval and Post-Retrieval.
The Pre-Retrieval process is added to ensure the most relevant documents will be selected: it improves the query to select the most relevant documents. This phase may include:
- Query Routing using metadata or semantics;
- Query Rewriting when LLM tries to generate a more optimal query;
- Query Expansion when LLM expands a single query into multiple queries.
To integrate selected chunks into the model prompt in the most efficient way, the Post-Retrieval process is used. It uses techniques like chunk reranking, summarizing, and fusion to avoid information overload and irrelevant details.
2.4. Self-Reflective RAG
To avoid factual inaccuracies of generated responses, the Self-Reflective Retrieval-Augmented Generation (Self-RAG) framework was introduced.
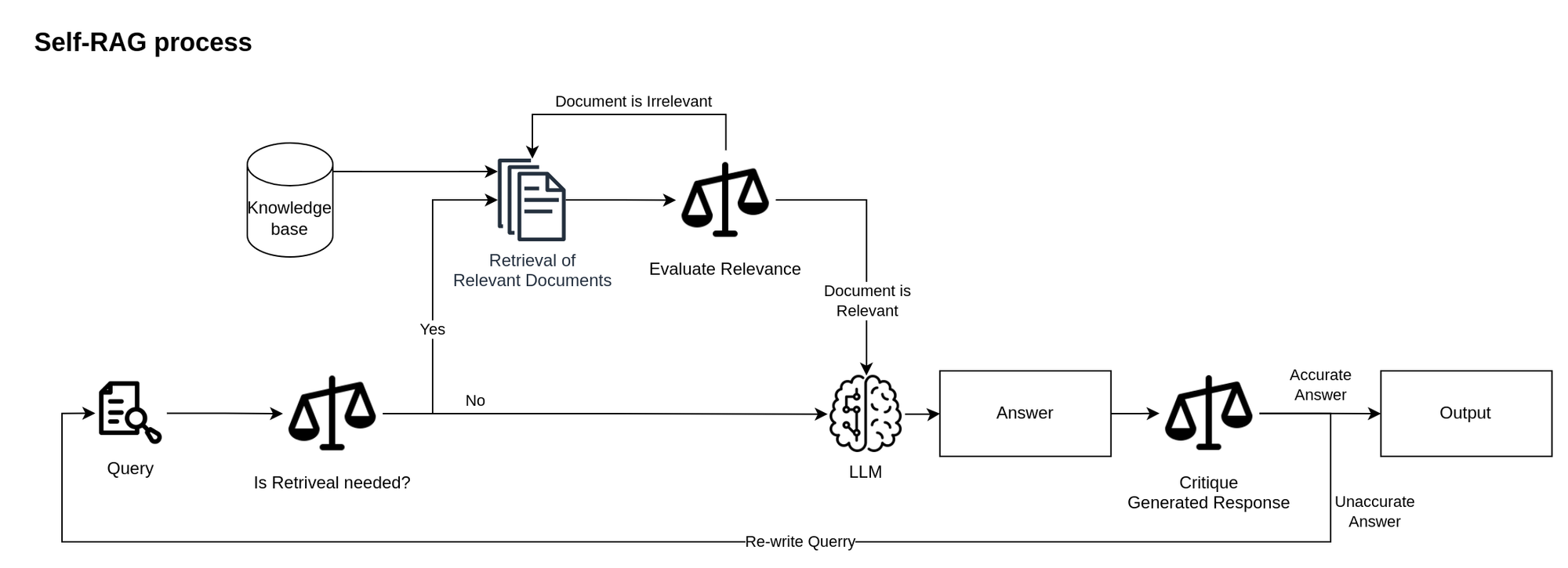
Self-RAG utilizes an adaptive retrieval mechanism when the model decides whether additional information retrieval is needed before generating an answer. If additional retrieval is executed, the model evaluates each retrieved document for relevance, ensuring the information aligns with the query requirements. After generating the response, it evaluates the output in terms of an answer’s overall utility and support by the retrieved information.
This reflective process improves the reliability and actuality of LLM’s responses, ensuring they are supported by sources and reducing the risk of hallucinations. The optionality of retrieval allows the model to generate creative and more personal answers if required.
2.5. Corrective RAG
Another technique to enhance the relevance of retrieved documents is Corrective Retrieval Augmented Generation (CRAG). CRAG introduces a corrective mechanism that improves the robustness of RAG by ensuring the retrieved documents are relevant and accurate. This is particularly effective when working with LLM on custom data sets or enhancing LLM with data curated for specific tasks. CRAG allows you to not limit your LLM with data stored but use knowledge from much larger and dynamic corpora – the entire web.
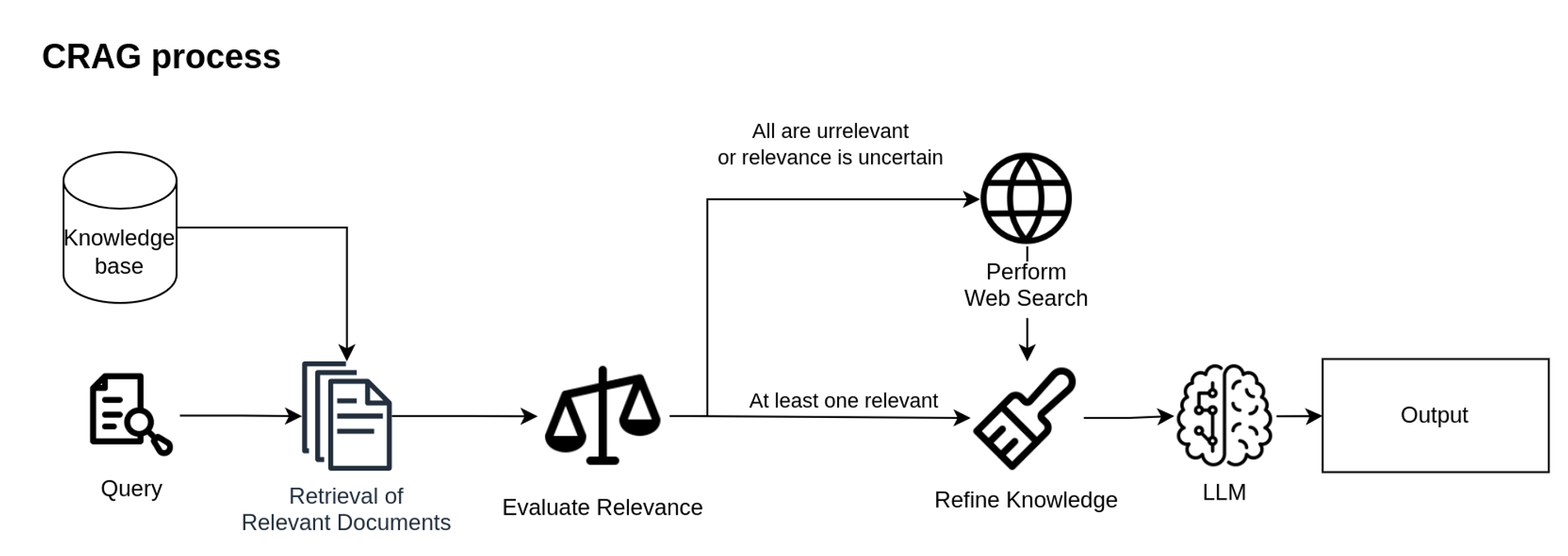
CRAG uses a lightweight retrieval evaluator to assess the quality of each question-document pair individually. Based on the evaluator confidence degree different actions are triggered:
- If any document is considered relevant, retrieval documents are refined;
- If all documents are irrelevant they are discarded and replaced by web search results;
- If the relevance of the documents is uncertain, CRAG uses refined documents along with external knowledge also using a web search.
CRAG proposes the next Knowledge Refinement process:
- Each retrieved document is segmented into fine-grained knowledge strips;
- The retrieval evaluator calculates the relevance score of each knowledge strip;
- Based on these scores, irrelevant strips are filtered, and relevant concatenated.
This process ensures that LLMs with custom data not only receive the most suitable information but also enhance the quality of the input data, leading to more accurate and reliable outputs.
2.6. Fine-tunning of pre-trained model
Implementation of Retrieval Augmented Generation (RAG) technologies, although effective, can become costly with intensive use or huge retrieved knowledge with extensive context requirements due to the price associated with processing large volumes of tokens.
An effective way to manage these costs with available custom data is by integrating knowledge from the data straight into model weights, reducing the need to repeat external data for every query. This could be achieved by fine-tuning LLM or developing a custom LLM.
Fine-tune allows the incorporation of domain-specific data into existing pre-trained models. In this process, we get a foundational model and continue its training using our custom data. This allows us to save general knowledge obtained during the extensive pre-training process enabling large language models to generate more accurate outputs using newly learned information.
Full fine tuning LLM models requires lots of computational resources because current LLMs have incredible sizes. Researchers proposed cost-effective methods of fine-tuning that allow training on more affordable hardware, potentially allowing fine-tuning on a single GPU.
Some of the parameter-efficient fine-tuning techniques:
- LoRA: Low-Rank Adaptation of Large Language Models proposes to freeze the pre-trained model weight and train only rank decomposition matrices, injected into model architecture. This allows significantly reducing the number of trainable parameters which leads to higher training throughput, and lower GPU memory requirements at a bit lower accuracy than full fine-tuning.
- DoRA: Weight-Decomposed Low-Rank Adaptation decomposes the pre-trained weight into two components, magnitude, and direction. Both of these components are fine-tuned with the LoRA technique applied for the direction component. This method provides better accuracy than LoRA maintaining low trainable parameters count.
- QLoRA and QDoRA are quantized variants of those methods which means they work with parameters in smaller precision allowing fine-tuning with even smaller computational resources needed.
These fine-tuning variants allow us to tailor large models to specific needs without outstanding costs associated with large language model training.
2.7. Development of custom model
If fine-tuned model capabilities do not meet the demands of your highly specialized tasks, developing a custom model from scratch may be necessary. You may train an LLM on your own data only when you have access to huge amounts of diverse and high-quality data.
Development and training an LLM on custom dataset require high-level expertise and exceptional computational power.
Training of such models involves multiple steps:
- Training infrastructure setup: setup hardware and software needed for LLM training;
- Data collection and preparation: collect and preprocess extensive datasets;
- Architecture selection: choose the model architecture that fits the task;
- Experimentation: conduct tests to debug training and optimize hyperparameters;
- Training: train LLM on custom data;
- Evaluation: check model performance.
The decision to build custom training LLMs is a significant investment associated with high costs for development and maintenance.
3. Summary
Technologies choice for integrating LLMs with custom data should align with your specific use cases. Selecting the right approach depends on your unique needs, time, and cost budget. Properly integrated LLMs help you serve your customers with accurate, personalized, and latest answers.
| Approach | Required Effort | Knowledge | Use Case |
| Out-Of-Box LLMs | Lowest | Obtained during training | Generic queries |
| Prompt Engineering | Medium-High | Static knowledge format | Domain-specific queries with limited diversity |
| Naive RAG | Low | Retrieved from internal store | Domain-specific up-to-date information with the acceptable possibility of confused or irrelevant answers |
| Advanced RAG | Medium | Retrieved from internal store | Complex queries requiring high accuracy and up-to-date information |
| Self-Reflective RAG | Medium | Retrieved from internal store | Queries requiring additional verification of retrieved data |
| CRAG | Medium | Retrieved from internal store + queried from web | Queries requiring high factual accuracy with dynamic integration of external data |
| Fine-tune pre-trained model | High | Obtained during pre-training + enhanced during fine-tuning | Domain-specific tasks without real-time data integration |
| Custom model | Highest | Obtained during training | Highly specific tasks requiring knowledge non-intersecting with general data without real-time data integration |
Note that LLM fine tuning or usage of custom models does not exclude other approaches like prompt engineering or RAG. A combination of these approaches could be employed to leverage the strengths of each, allowing incorporation of domain-specific knowledge directly into model parameters along with dynamical data integration.
Example Use Cases
Personalized Health Response
- Task: Provide personalized answers for health-related questions.
- Custom data: Existing user profiles (age, weight, chronic diseases, allergies, etc).
- Recommended approach: Prompt Engineering for LLM pre-trained on medical texts.
- Benefit: Responses based on individual profiles without the need for an extensive knowledge base.
Product Recommendation System
- Task: Help the user find items from your website specific to his requirements.
- Custom data: Items on your web store (descriptions, features, and real-time availability).
- Recommended approach: RAG-like.
- Benefit: Dynamically integrates the most relevant and up-to-date information about products or services.
Partnering with a company that has deep knowledge and experience in the machine learning and implementation of LLM-powered systems, such as blackthorn.ai is crucial for the delivery of a high-value LLM-powered system. To discover how LLMs with custom data can benefit your business and to determine the optimal approach for your needs, book a meeting with our experts today.
FAQs
What are the benefits of integrating custom data with LLM?
Integrating LLM applications with custom data enhances model domain-specific knowledge, allowing more personalized and accurate answers. The integration also allows LLMs to consider real-time data, improving the relevance of their outputs.
What is Prompt Engineering and Retrieval Augmented Generation (RAG)?
Prompt Engineering and Retrieval Augmented Generation are techniques for the integration of external data with LLMs without changing model weights. Prompt Engineering allows static data ingestion while RAG allows dynamic data selection based on the question.
What techniques are used for embedding custom knowledge into LLM parameters?
To embed knowledge from custom data fine-tuning techniques or the development of a custom LLM model may be applied. Fine-tuning allows you to continue training LLM on custom data, saving general knowledge from pre-training.

