
Introduction
In the modern digital landscape, data is the new oil, driving innovation and decision-making across industries. However, the majority of this data is unstructured, scattered across the web in various formats, from websites and social media platforms to forums and blogs. It’s estimated that over 80% of enterprise data is unstructured, and the volume of this data is growing exponentially. According to IDC, the global data sphere is expected to reach 175 zettabytes by 2025 [reference]. Despite its vast potential, this data often goes underutilized. Businesses struggle to harness their full value, leading to missed opportunities and inefficiencies.
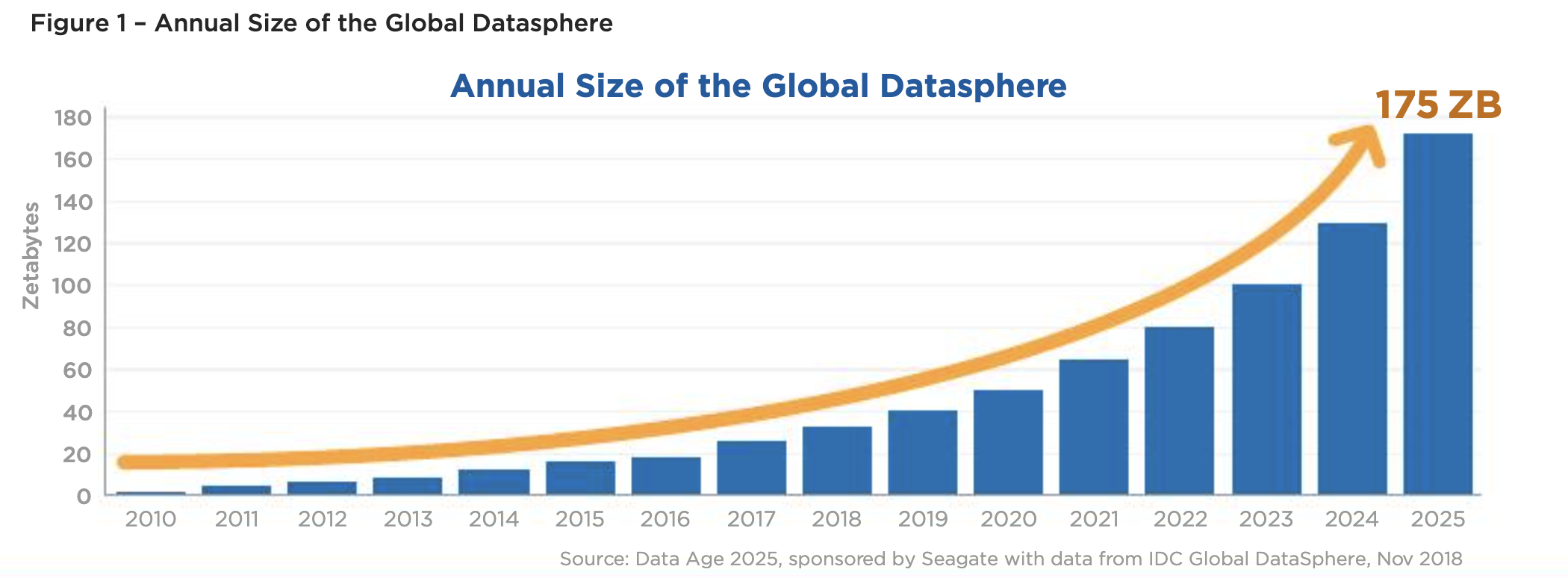
Figure 1: Growth of Global Data Sphere (2010-2025)
The problem is clear: Much data is not used, or not used well enough. The key to overcoming this challenge lies in effective information extraction, transforming unstructured data into data that is easy to process and extract actionable insights. Without the right tools, extracting valuable insights from this sea of unstructured data is a daunting task, leading to missed opportunities and a competitive disadvantage.
The Challenges of Information Scraping and Data Mining
Information scraping and data mining are powerful techniques for extracting valuable insights from unstructured data, but they come with their own set of challenges:
- Data Diversity: The web is filled with data in countless formats, from plain text and HTML to JSON and XML. This diversity makes it difficult to design a one-size-fits-all scraping solution.
- Website Complexity: Modern websites are often dynamic, requiring sophisticated scraping techniques to navigate through JavaScript-heavy pages or handle CAPTCHA and anti-bot measures.
- Data Quality and Relevance: Not all scraped data is valuable. Identifying and extracting relevant information from noise is a key challenge in data mining.
These challenges often result in businesses either struggling to implement effective scraping solutions or investing significant resources to manage the process manually, which is neither scalable nor sustainable.
The Legacy Approaches: Why Traditional Methods Fall Short
Traditionally, information extraction was done through manual document parsing and optical character recognition (OCR). These legacy approaches were marked by significant limitations:
- Labor-Intensive and Slow: Extracting information manually or using rudimentary OCR methods require extensive human effort, making the process both time-consuming and costly.
- Limited to Text Data: These methods primarily focused on text data, making them ineffective for documents with complex layouts, images, or other non-textual elements.
- Fragile Parsing Rules: The rules used for parsing were often brittle, requiring constant updates, and prone to failure when applied to different types of documents.
- High Development Effort: Every new document type demanded custom tuning and extensive verification, making the process inefficient and hard to scale.
These challenges meant that businesses were often left with incomplete or inaccurate data, limiting their ability to make data-driven decisions effectively.
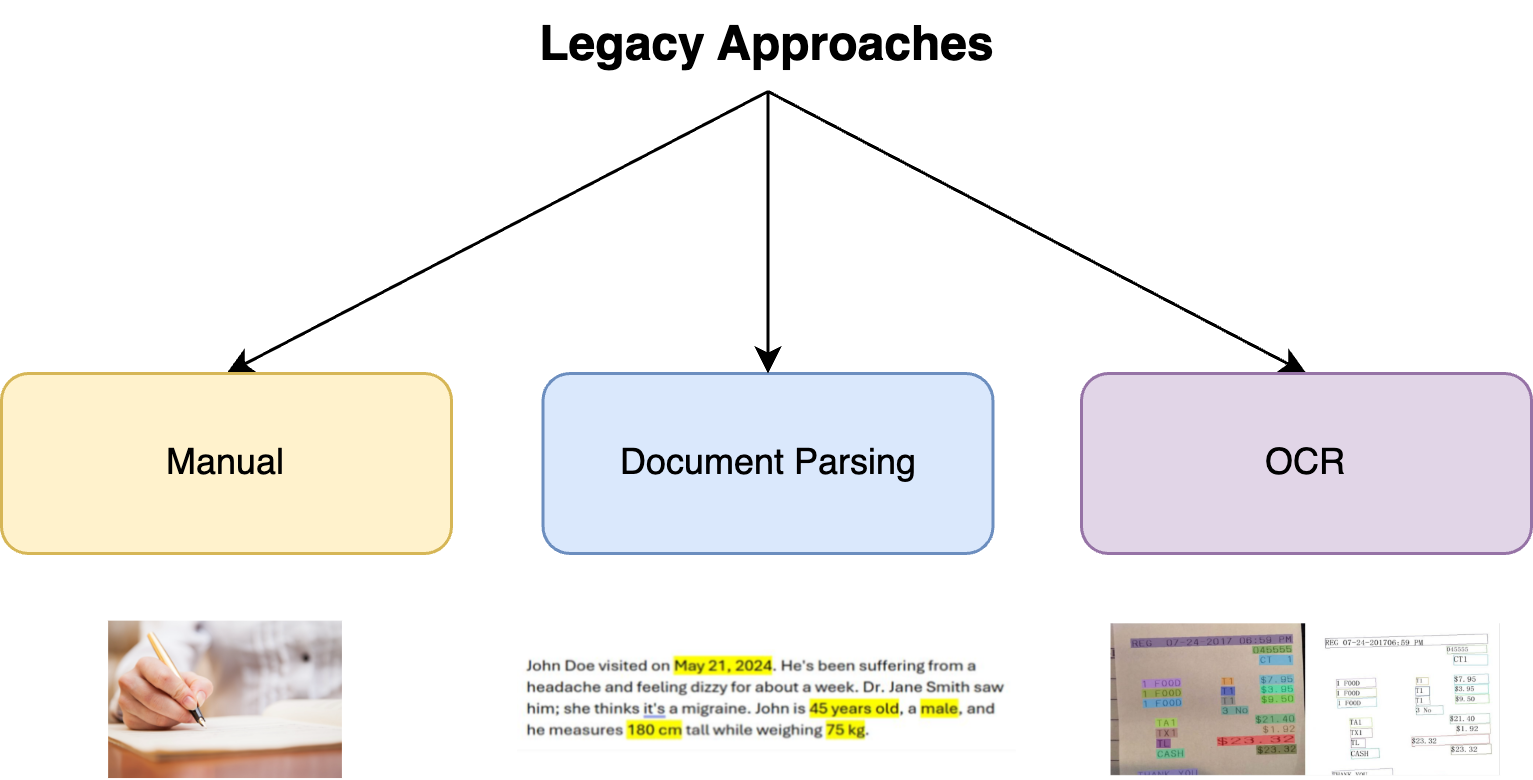
Figure 2: The Three Main Traditional Approaches to Information Extraction.
The Modern Solution: Leveraging AI and LLM + RAG
Modern information extraction has evolved significantly with the appearance of Large Language Models (LLMs). It is combined with Retrieval-Augmented Generation (RAG) into an approach that revolutionizes how businesses can harness unstructured data. By combining LLMs with RAG, organizations can now extract information from a wide array of sources, including files, databases, and other diverse forms of unstructured text.
- Reduced Development Efforts: Unlike legacy methods, LLM + RAG significantly lowers the development burden. These systems adapt seamlessly to different document layouts, reducing the need for manual intervention.
- Enhanced Accuracy and Context Understanding: The advanced AI-driven models provide a more nuanced understanding of context, improving the accuracy of the extracted data and minimizing errors.
- Scalability and Efficiency: This modern approach allows for the rapid processing of large volumes of data, making it a scalable solution for enterprises dealing with vast amounts of unstructured information.
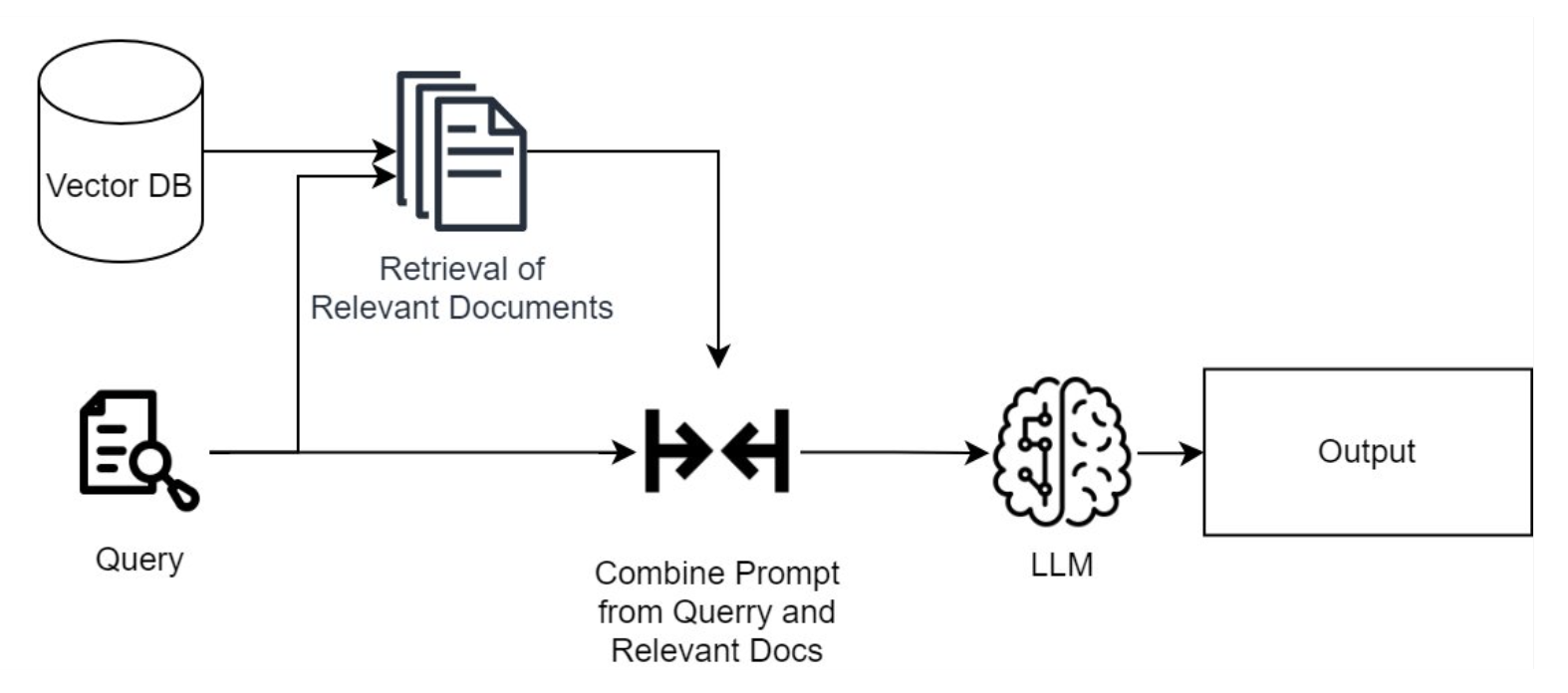
Our AI-Powered Information Extraction Solution
Understanding these challenges, we have developed a cutting-edge solution that simplifies information scraping and data mining. Here’s how it works:
- Sophisticated Web Scraping: Our tool begins by scraping the websites you specify, intelligently navigating complex site structures, and loading dynamic content.
- AI-Driven Analysis: It then uses advanced AI LLM algorithms to analyze the scraped data, filtering out irrelevant information and extracting the insights that matter most.
- Generating Custom Structured Output: The final step is delivering the data in the format you need, whether that’s structured tables, JSON, or another format, ready for integration into your workflows.
This tool is designed to make information scraping and data mining more accessible, efficient, and reliable. Whether you’re looking to gather competitive intelligence, monitor market trends, or simply make better use of the data available online, our tool has you covered.
To illustrate how our AI-powered solution stands out compared to traditional methods, we’ve outlined the key differences below:
| Traditional Methods | Our AI-Powered Solution | |
|---|---|---|
| Accuracy | Struggle to extract needed information with complex or dynamic websites. | ✅ Extracts relevant data accurately using AI, even from dynamic sites. |
| Scalability | Hard to scale to different layouts. | ✅ Adapts automatically to any website, and supports up to 5 different websites per one request. |
| Output Flexibility | Additional processing is often required to transform the data into the desired format. | ✅ Delivers ready-to-use outputs in many known formats such as JSON, CSV, etc. |
| Development Effort | Involves custom scripts development and frequent updates. | ✅ Ready to use, no setup, low or no maintenance needed. |
| Efficiency | Time-consuming: Manual processes slow down information extraction and increase costs. | ✅ Automates the entire process, delivering results in less than a minute. |
| User Experience | Often requires additional technical knowledge to operate and maintain. | ✅ User-friendly, no technical expertise required. |
Our AI-powered solution offers a more efficient, scalable, and accurate approach to information extraction, enabling businesses to unlock the full potential of the data.
Conclusion
Information scraping and data mining are essential processes for unlocking the value of unstructured data. However, they come with significant challenges that can hinder their effectiveness. Our AI-powered tool is built to address these challenges head-on, providing a seamless, automated solution for extracting and analyzing data from the web.
By simplifying the scraping process, enhancing data quality with AI, and ensuring legal compliance, our tool enables businesses to harness the full potential of the data available online.
